|
SPRAAK
|


All Data Structures Namespaces Files Functions Variables Typedefs Enumerations Enumerator Groups Pages
|
SPRAAK
|
The ProSpect representation used for the cluster Gaussians is a linear transformation of the log-spectra. It contains a low-order cepstral component and the log-spectrum projected onto the subspace spanned by the cepstrum. This projected component has the same dimensionality as the original log-spectrum, so the total feature size will increase. This linear ProSpect transformation is to be applied to the statics as well as to the delta's. Example call to create the transformation matrix (-oprosp) for 22 log-spectral features using cepstral coefficients 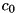 ...
... 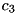 (a good choice according to [3]):
(a good choice according to [3]):
To generate ProSpect features from log-spectra, include a [lin_comb] block in your spr_sigp script:
Add delta (derivative) calculation after this block.
When ProSpect features are modeled with a Gaussian mixture with diagonal covariance, an obvious modelling error is made: diagonal covariance would imply independent components, while this is not the case due to the linear dependency (this is actually also true for the log-spectral feature vector). Unmodelled correlations can be compensated for with a stream exponent [3]. The exponents file (prospect.exp) is also generated by the spr_mdt_make_prospect_mat.py script and will be required in the programs below. A good value for the exponents is 1 for the cepstral part (-exp_cep) of the ProSpect features and 0.5 for the projection part (-exp_prj). The exponents file contains the stream exponents for the statics and the delta's, which are all equal (-Ndelta 2 if you are using static, velocity and acceleration streams).
The acoustic model is trained as described in the preceeding sections of this manual. The MDT recognizer has been tested in conjunction with a MIDA backend model. This backend model can be trained on clean speech, but we have observed that multi-condition training has a positive effect. See [1] and [2].
The program to create the cluster Gaussians is spr_mdt_make_cg.py - see reference manual. It prunes back a phonetic decision tree to have -Nc leaves, each characterized by a Gaussian trained with -Nem EM iterations. The cluster Gaussians contain the static and delta streams, have a diagonal covariance in the ProSpect domain and are trained on clean data with cepstral mean normalization, as can be seen in the spr_sigp script in the following example to generate 700 (-Nc option) Gaussians:
where -obs, -suffix, -tmp and -Nthread follow the normal conventions; -ci, -cd, -q, -tree are obtained in context-dependent model training; -seg is a segmentation file (into tied states) which can be obtained with spr_vitalign.py. The result is the -cg file.
The cluster Gaussians depend on the acoustic features used but also to some extent on the language of the ASR system. To play safe, a new language requires a new set of cluster Gaussians.
The program to create the association table is spr_mdt_make_cgt.py - see reference manual. On clean data, it makes or forced alignment (or uses a segmentation file) and finds which of the cluster Gaussians has the best score and maintains the statistics. The following call makes an association table with maximum 7 (-l option) cluster Gaussians per backend Gaussian. The association table is further pruned with the -p option to remove weak associations.
-tbl and -stats are the outputs. -ssp is a spr_sigp script that generates the backend (MIDA in this case) and frontend (ProSpect) in one vector (in this order). -h -g -ci -cd -sel for the backend acoustic model
The association table should be rebuilt if either cluster Gaussians or backend Gaussians change.
[1] Jort Florent Gemmeke, Yujun Wang, M. Van Segbroeck, Bert Cranen and Hugo Van hamme. Application of noise robust MDT speech recognition on the SPEECON and SpeechDat-Car databases. In Proc. INTERSPEECH2009 – 10th annual conference of the international speech communication association, Brighton, U.K., September 2009.
[2] J.F. Gemmeke, M. Van Segbroeck, Y. Wang, B. Cranen and H. Van hamme. Automatic speech recognition using missing data techniques: Handling of real-world data. In D. Kolossa and R. Haeb-Umbach, editors, Robust Speech Recognition of Uncertain or Missing Data, Berlin-Heidelberg (Germany), Springer Verlag. 2011.
[3] Hugo Van hamme. PROSPECT Features and their Application to Missing Data Techniques for Robust Speech Recognition. In Proc. International Conference on Spoken Language Processing, volume I, pages 101–104, Jeju Island, Korea, October 2004.
 1.8.6
1.8.6