|
SPRAAK
|


All Data Structures Namespaces Files Functions Variables Typedefs Enumerations Enumerator Groups Pages
|
SPRAAK
|
The favorite acoustic modeling technique in SPRAAK is semi-continuous HMMs (SCHMM) with diagonal covariance gaussians. In this setup each distribution in the acoustic model is computed as a weighted sum of gaussians drawn from a large pool. It is used as a generic approach that allows untied and fully tied mixture as extremes of its implementation.
In semi-continuous HMMs the model of the observation probabilities is organized in two layers, consisting of:
In semi-continuous HMMs the number of basis functions tends to be very large (several thousand), while only a few of them (typically around 100 in SPRAAK) will have non-zero weights for any individual state.
Assume:
 = feature vector
= feature vector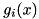 = basis function i
= basis function i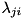 = the weight of mixture i in state j
= the weight of mixture i in state j then, the probability of observing 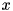 in state
in state 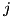 is given as:
is given as:
![\[ f_j(x) = \sum_i{ \lambda_{ji} g_i(x) } \]](form_21.png)
In the case of diagonal convariance tied Gaussian mixtures (default) with:
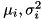 = mean and variance of mixture i
= mean and variance of mixture i the above expands to:
![\[ f_j(x) = \sum_i{ \lambda_{ji} \frac{1}{|2\pi|^\frac{D}{2} \prod_k \sigma_i^2(k)} \exp \left( - \frac{1}{2} \sum_k \frac{(x(k) - \mu_i(k))^2}{\sigma_i^2(k)} \right) } \]](form_23.png)
Obviously the above concept easily accomodates commonly used other variants of tying:
While SPRAAK will function correctly for all types of tying, there are a number of (computational) optimizations from the viewpoint of a semi-continuous system.
In semi-continous modeling the weight matrix linking basis functions to states tends to be very sparse (i.e. most weights are '0'). SPRAAK accomodates a flexible sparse data structure by putting the information in 3 separate files (typically with the same basename, e.g. 'acmod'): d
The files used for storing HMM parameters are described in more detail in HMM Files.
The acoustic model returns NORMALIZED scores for a segment of data. By default the Viterbi algorithm is used, but other computational approaches and other acoustic models (than the standard SCHMM) are possible.
'NORMALIZED' implies that the sum of scores over all possible states for any given time instant will be equal to 1.0. In practice log10-probabilities are returned. Thus:
![\[ f(x_t) = \sum_j f_j(x_t).P(j) \]](form_24.png)
![\[ L(x_t) = \log_{10} \prod_t \frac{f_j(x_t)}{f(x_t)} \]](form_25.png)
where: 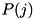 = the prior probability for state j
= the prior probability for state j
The motivation for using these normalized scores is:
All probabilities in SPRAAK that are stored in files are by default given as log10() values.
SPRAAK uses an efficient bottom up scheme to predict which gaussians in the pool that need to be evaluate and which ones not. This is done for the whole pool of gaussians at once and not on a state by state basis. The datastructure describing for each axis which regions are relevant for which gaussians is computed once when the acoustic model is loaded.
More information on setting paramters for the FROG system may be found in rm_gauss.c
 1.8.6
1.8.6