Overview
Figure 1 gives an overview of the main components of the SPRAAK recognizer in a typical configuration and with the default interaction between these components.
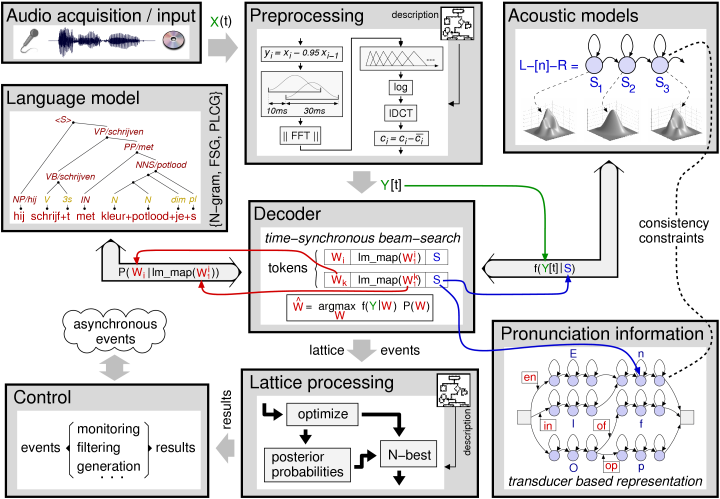
Figure 1
When using the SPRAAK engine for other tasks (e.g. training of acoustic models), a subset of the same main components is used. Hence, we limit the subsequent description to the recognition setup since this is the most general case. Note that for highly experimental setups, more complex configurations and interactions are possible;
figure 1 only depicts a typical configuration.
The main components is the system are:
-
the preprocessing (which includes a whole set of processing modules)
-
the acoustic model (AM)
-
the pronunciation information, organized as a network / finite state transducer
-
the language model (LM)
-
the decoder which connects all major components together
-
a lattice generation and processing block (which includes a whole set of lattice processing modules)
All major components are implemented as dynamic objects with well defined interfaces. For most objects, several interchangeable (at run-time) implementations are available. For example, there is a standard N-gram LM as well as a finite state based LM. These two implementations can be combined with an extension layer providing class-based grammars, sub-models, linear combination of LM's, and so on.
Whenever this is beneficial an extra interface layer (called a gateway) is added to the object to isolate the static data (e.g. the language model data itself) from the temporary data needed when interacting with that resource. These gateways also provide fast access (eliminating the dynamic binding) to the main functionality of an object.
To allow intervention inside the core components of the SPRAAK system without needing to recode any of these core components, observer objects are allowed at strategic places in the processing chain. Observer objects also allow easy monitoring and filtering of (intermediate) results.
Having a fast system as well as a system that is flexible enough to allow all possible configurations of modules with whatever interaction between these modules, is challenge to say the least. In order to provide the best of both worlds, SPRAAK provides both a generic and hence fairly slow implementation and several efficient but more constrained implementations. By making good use of templates, it is possible to write generic code, i.e. code that imposes as few limitations on the interactions between the components as possible, from which efficient code for a specific setup is derived automatically just by redefining a few templates.
All four core techniques used to make the SPRAAK engine as flexible as possible –objects, gateways, templates and observers– are further clarified in the section Design choices: objects, gateways, observers and templates.
Next to the main components, there are several auxiliary components and/or objects. The most important ones are handled in sections The preprocessing till Other objects. For a complete enumeration of all objects and methods, we refer to the low level API.
Design choices: objects, gateways, observers and templates
Objects
Principles
Although SPRAAK is mainly coded in C, all major building blocks are encoded in the form of objects. These objects are designed for dynamic binding, i.e. the function that must be called when method 'X' is requested for object 'Y' is determined at run-time. This is similar to the dynamically typed objects used in languages such as objective-C, Smalltalk or Python, and contrasts to objects in C++ which are statically resolved (except when using virtual methods). However, SPRAAK also provides means to enforce static (i.e. at compiler time) checking of the arguments. Such strong type checking helps in finding and resolving bugs at compile time (i.e. during the development).
Rationale
A speech recognition engine such as SPRAAK is a large and complex system. The use of objects is an effective method to split the system into manageable units for which the interaction is completely defined by their interface (methods and public members). Encoding the major components as dynamic objects provides the possibility for easy replacement of each of the components in the recognizer. When combined with the possibilities of dynamic link libraries, this provides plug&play replacement of all major components in the recognizer. This makes that even those who only have access to the binaries (no source code license) can expand or modify the system, without the need to recompile anything, except for their own new additions.
On the other hand, a speech recognition engine must be very efficient if it is to be useful at all. There are tight limits on both computational and memory resources for the system to be useful: real time operation is a must for most applications and even research becomes impossible if the system is too slow or consumes too much memory. To achieve these goals, the following choices were made:
-
C is used as the main programming language. C is designed as a low overhead language and is as such ideally suited in situation where maximal control over memory and computational resources is needed. The use of C also guarantees that the SPRAAK libraries can be used (linked) when using a different programming language for your project. However, C is not an object-oriented language, so some additional conventions and code are needed to define the objects and to provide the basic functionality (defining inheritance, resolving methods, ...). For details on the actual implementation of objects, we refer to the programmers manual.
-
To keep the overhead of the dynamic binding low, only the major components are encoded as dynamic objects.
-
Whenever needed, gateways or function pointers are used to further limit the overhead of the dynamic binding (see gateways).
-
For typical configurations, highly specialized and optimized implementations are available (see templates).
Gateways
Principles
Objects that represent resources are accessed by means of gateways, allowing different sub-systems or program threads to use one or more resources simultaneously. A gateway is lightweight layer in between the code using the resource and the object representing that resource. Next to simultaneous access to the same resource, gateways also enable the resource to be used efficiently for a certain usage pattern. To serve both these purposes, gateways contain at least the following items:
-
Quick access pointers (public) to the methods that are typically needed given the intended use of the resource.
-
Quick access pointers (private) to the data structures needed given the intended use of the resource.
-
Temporary storage needed for the intended use of the resource.
Since some objects have more than one usage pattern, there can be multiple types of gateways to the same resource. For example, acoustic models have an evaluation and a training gateway.
Rationale
For most components (objects) in the SPRAAK system, the data needed to actually use that component can be split in two parts: (1) a large chunk of actual resource data (e.g. the acoustic model) and (2) some local storage needed to do something with this data (e.g. the vector needed to return state probabilities). In the light of concurrent use of the resource, an effective means to isolate that part of the data that can be re-used is needed. Gateways provide this functionality, and hence assure efficient re-use of the main resources in the SPRAAK system.
Concurrent use of resources is useful in several situations. For example, in a multi-threaded system, it allows for multiple concurrent and independent queries to the same acoustic model. These multiple queries can either be on different frames of the same utterance, hence speeding up the processing, or on different inputs in a multi-user platform. Even in a single-threaded system, the same resource can be used on different locations in the processing chain. For example, the N-gram language model used in the first decoding pass to generate a word lattice can be re-used later on in the lattice rescoring pass as well.
Next to providing shared resources, the use of gateways in SPRAAK serves two additional purposes:
-
Gateways prepare the resource optimally for a given usage pattern, hence speeding up the subsequent processing.
-
Gateways add an extra abstraction layer, providing an effective means to add support for third-party implementations (e.g. existing language modeling tools).
Observers
Principles
Observer objects can be inserted on predefined strategic positions in the processing chain. Observers have their own storage and can observe and sometimes even modify the system state at that point in the processing chain. As such, observers can be used to monitor the process, to add extra functionality or even to modify the behaviour of the system.
Rationale
The use of objects and dynamic libraries allow for a flexible combination of the core components. Observers extend on this flexibility by allowing some intervention within the internal operation of core components (mainly the search) without having to modify the code of the core components.
The associated overhead for allowing observers at a certain position in the processing chain is low (it requires only a simple check on a member variable in an object/structure). Yet at the same time, allowing observers to be inserted at strategic positions opens up a whole new set of possibilities. Some examples are:
-
The progress of the recognition process can be monitored, and can be influenced if desired (e.g. assuring real-time behaviour).
-
All kinds of feedback loops can be added, allowing for speaker adaptation, noise adaptation, language model adaptation, ...
-
Extra information can be stored for later use. This allows us to re-use the forward-pass only decoder in a forward-backward fashion.
Templates and optimal task-specific implementations
Principles
Templates allow for the same piece of code to be re-used in different situations (and even for different objects) without any overhead. This is done by modifying the behaviour of the code at compile time.
Rationale
SPRAAK is designed to be very flexible: it allows several behavioural changes at run-time and imposes few restrictions on the interaction between the objects. The techniques used to obtain this flexibility (dynamic objects, gateways, observers) were chosen and designed for low overhead. However, there is a very noticeable impact when comparing the generic code path (i.e. the one that provides maximal flexibility w.r.t. to options and interconnections) to a trimmed down task-specific implementation. Therefore, we opted to offer several efficient but more constrained implementations next to the generic implementation. By making good use of templates, it is possible to write generic code, i.e. code that imposes as few limitations on the interactions between the components as possible, from which efficient code for a specific setup is derived automatically just by redefining a few templates. In other words, templates reduce the overhead for implementing and maintaining such specific code paths. At run-time, the SPRAAK system automatically chooses the most efficient implementation given the capabilities and interactions of the components used in the speech recognition system one configures. So, from an end-user perspective, the whole system behaves transparently.
Some examples of the use of task-specific code are:
-
In several situations the LM-component in figure 1 is not needed. If the LM-constraints are trivial (e.g. a single sentence when doing training or supervised adaptation of the acoustic model, or a simple finite state LM), all information can be encoded more efficiently in the pronunciation network. There is a specific decoder for this common situation.
-
Most decoders only show the interaction depicted in figure 1 (i.e. the LM does not need to know the state of the decoder, preprocessing or acoustic model, ...). Furthermore, since the outcome of the acoustic model only depends on the preprocessed frame, a more efficient implementation that evaluates all states (see acoustic model for more details) can be used. Again, for this situation, a specific decoder is available.
Corollaries of the design choices
The design choices made in SPRAAK (objects using C, gateways, templates) result in a very flexible system (plug&play replacement of all major components, flexible configuration, ...) with minimal impact on the efficiency. There are however also some associated costs:
-
C is in se not an object-oriented programming language. It is possible to provide a descent framework, but this framework is sub-optimal (readability of the code, ease of use, compiler support for error checking) compared to a real object-oriented language.
-
SPRAAK objects are yet another convention, and hence require the programmers that want to extend SPRAAK to learn these conventions.
-
SPRAAK does not use objects for `small' components. Using objects for `small' components as well may result in more readable (self-documenting) code. However, prior examples and trials have shown that this introduces too much overhead.
-
Although gateways are an effective means to share resources, the current implementation limits this sharing to static data. Adapted data (e.g. speaker adaptation of an acoustic model) cannot be shared.
-
Observers allow some intervention into the operation of the core components. However, the possible interventions are limited to certain predefined strategic points, and as such, they cannot eliminate the need for source code interventions completely.
-
For all core components in the SPRAAK system, a serious effort was made to write (very) efficient code. This assures that SPRAAK can be used in real applications without compromises. However, highly efficient code is also more difficult to read or extend on, and in some cases, the efficient organization of data may imply some restrictions when extending the functionality of these components. In other words, not all core components in the SPRAAK system are good starting points for new implementations. Check out the descriptions of the specific components in the SPRAAK system for details.
Functionality and interactions
Todo
The preprocessing
The preprocessing converts audio data (or half preprocessed features) to a (new) feature stream. The preprocessing consists of a fully configurable processing flow-chart and a large set of standard processing blocks.
Each processing block provides the following six methods:
- help
- return the explanation (on-line help) concerning the configuration parameters this processing block takes (setup method)
- status
- print out the current status (debugging)
- setup
- create a new object given a set of configuration parameters
- process
- process a single frame of data or return a previously 'held' frame
- reset
- reset all variables that change during processing, i.e. prepare to start working on a new data file
- free
- destroy the preprocessing object
The process method is not limited to direct feed through processing, i.e. an input frame does not have to be converted immediately to an output frame. Non-causal behaviour is supported by allowing the process routine to withhold data whenever deemed necessary. The silence/speech detector for example looks a certain amount of frames into the future in order to filter out short bursts of energy (clicks). The process method can also be requested to return previously withheld data, even if no new input data is available. Next to returning output or withholding data, the process method can also skip data (throw a frame away) or signal an error.
The constraints imposed on the preprocessing blocks are:
-
Each frame must be either processed and output or skipped.
-
Frames must be returned in the correct order.
-
Each processing block has to store whatever 'contextual' data it needs; there is no provision for looking at previous or future input frames.
The configuration of and interaction between the processing blocks is governed by a supervisor object. When processing data, the supervisor is responsible for calling the different processing blocks in the correct order and with the correct data. In a sense, the supervisor converts a complex pipe-line of elementary processing blocks into a new elementary processing block. Next to the help, status, setup, process, reset, and free method, the supervisor also offers the following high-level methods:
-
fseek: Reposition an input file and the processing pipe-line so that the next output frame is the requested one. The fseek method can operate in two modes. By default, it behaves as if each file is processed as a whole after which the requested block of frames is extracted. Alternatively, one can also first select the requested frames (must be a single continuous block) from the input and only process those frames. To illustrate the difference between the two modes, assume a processing block that subtracts the mean from a signal and assume one wants to process all phonemes /e/ in a database. By default, the mean is calculated based on the complete input file. In the second mode, the mean would only be calculated on the selected data (a single phoneme /e/).
-
Methods to handle the configuration parameters (reading/constructing them, passing them to the individual processing, resolving error locations, ...)
-
Several methods to help in working with databases (organized collections of individual files).
-
Methods to look up basic processing blocks and to setup feedback loops or other interaction schemes.
-
Methods to store preprocessed data for re-use in a second pass. This allows for example the backward pass needed for Baum-Welch training.
The most important properties of and constraints on the preprocessing are:
-
All preprocessing can be done both on-line and off-line. The fact that everything is available on-line is very handy, but requires some programming effort whenwriting new modules since everything has to be written to work on streaming data.
-
The supervisor and most processing blocks are designed for low latency, i.e. input data is only withheld when necessary and withheld data is output as quickly as possible.
-
Currently, the supervisor can only work with a single frame clock. Changing the frame-rate (dynamically or statically) is not supported.
-
Frames must be processed in order and are returned in order.
The acoustic model
Basically, the acoustic model calculates observation likelihoods for the Hidden Markov States (HMM) states the decoder investigates. In its most general form, the acoustic model can (1) provide its own state variable(s) to the search engine, (2) determine in full for which search hypothesis the state likelihood will be used, and (3) query all resources available to the search engine. Having its own state information allows the acoustic model to enforce a parallel search over some internal options (2D Viterbi decoding). For example, an acoustic model may contain a sub-model for males and females. By adding a male/female state to the search space, the acoustic model forces the search engine to investigate both genders in parallel (at least until one of the two dominates, resulting in the other one being removed due to the beam-search pruning). Having access to all information concerning the search state enables context aware acoustic models. Note that since the decoder only takes the acoustic model states into account when merging search hypotheses (tokens), the acoustic model state must reflect the piece of context information that is being used if the search is to be consistent (guaranteed to find the best solution if the search beam is wide enough).
The overhead introduced by this general framework is substantial. In order to allow the automatic selection of a more restrictive and hence faster interfacing between the search and the acoustic model, acoustic models must indicate which functionality they need. The fastest implementation assumes that the state likelihoods only depend on the input frame and the state numbers (cf. figure 1). If so, and if allowed by all other components used in the recognizer, the decoder switches to the following scheme to speed up the acoustic model evaluation:
-
Input frames are sent to the first stage of the acoustic modeling some time before they are needed (asynchronously). This allows (a part of) the acoustic model to work at its own pace in one or more separate threads.
-
When the search engine actually needs the likelihoods for a certain frame, it marks the HMM states for which the output likelihoods must be returned (if the acoustic models needs those marks) and calls the second stage of the acoustic modeling. By evaluating all needed states in one call, the communication overhead between search and acoustic modeling is kept to a minimum.
-
Since all likelihoods are now calculated in one go, the likelihoods can be normalized on a frame by frame basis. This results in scores that are more directly related to the posterior word probabilities (confidence scoring).
This alternative scheme is ideal for the fast acoustic models developed by ESAT, i.e. tied Gaussians and fast data-drive evaluation by means of the 'Fast Removal of Gaussians' (FRoG) algorithm. Other acoustic models such as multilayer perceptrons or discrete models using vector quantization also benefit from this scheme.
Next to the evaluation methods there are also methods for:
-
Reading and writing the acoustic models.
-
Initializing a new acoustic model.
-
Updating the acoustic models (training and/or speaker adaptation). Although there are currently no methods implemented for discriminative training due to lack of a clear standard, the framework does allow for implementions to be added.
-
Opening gateways to the acoustic model either for evaluation of for updating.
-
Accessing components of the acoustic model (the Gaussian set, FRoG, ...).
The language model
The language model (LM) calculates conditional word probabilities, i.e. the probability of a new word given its predecessor words. In its most general form the LM can –similar to the acoustic model– (1) provide its own state variable(s) to the search engine, (2) determine in full for which search hypothesis the word probability will be used, and (3) query all resources available to the search engine. Note that, as was the case with the acoustic models, the state variable(s) must be complete (reflect all dependencies of the conditional word probabilities) in order to obtain a consistent search.
Note that there is a crucial difference in the typical usage of the decoder for what concerns the language and acoustic model states. The normal acoustic model constraints, i.e. all information concerning the context dependent tied states is usually directly encoded into the pronunciation network as this is far more efficient, and hence no extra acoustic model states are needed. The language model constraints on the other hand, are typically separated from the pronunciation network since encoding them into the pronunciation network is either (1) not possible, (2) requires some approximations, or (3) provides little gain in decoding speed while requiring substantially more memory.
For most situations the following faster but more constrained scheme is to be preferred:
-
The LM condenses all relevant information concerning the word predecessors in its own state variable(s).
-
The conditional word probabilities only depend on these state variables. In other words, the LM state equals to the full LM context used by that LM.
This allows an intermediate LM cache system to resolve most of the LM queries, hence reducing the impact of a potentially slow LM sub-system on the overall decoding speed.
When interfacing with an LM (through a gateway), the following methods are available:
- lmcn
- Given an LM state, a new word and optionally some extra information concerning all other resources in the recognition system, return a new LM state and the corresponding conditional word probability. Note that there can be multiple new LM states and hence multiple conditional word probabilities. This allows for example for the word 'cook' to be used either as the verb or as the person in a class based LM. Whenever an end-of-word state is encountered in the pronunciation network (see pronunciation network), the decoder uses this method to update the search tokens so that they reflect the new situation.
- prob
- Given an LM state, a new word and optionally some extra information concerning all other resources in the recognition system, return (an estimate of) the conditional word probability. In case the combination of the current LM state and the new word leads to multiple new states, the highest conditional word probability is returned. This method typically runs substantially faster that the 'lmcn' method and is used by the decoder at the moment the word identity is found in the pronunciation network, which is usually some time before the end-of-word state is reached. Keeping the old LM-state until the end-of-word state is reached results in a faster decoder since the costly transition to a new LM state (there may be multiple new states, the LM needs to create the new state(s), and new LM states require some bookkeeping to be done by the decoder) are delayed until all phonemes in a word are observed and deemed good enough.
- lmcr
- Release an LM state. This method is optional since not all LM's need it. It indicates that a certain LM state is no longer used by the decoder, and hence all memory used to build this state variable can be reclaimed.
- lmc0
- Create the initial LM state.
- lmup
- Provide unconditional word probabilities. The unconditional probabilities are used to precalculate the best word probability over large word sets so that even if only the first phone of a word is known, some educated guess concerning the upcoming conditional word probability can be made. Good estimates speed up the decoder by some 30%.
- lmq
- Query about several aspects of the LM. This allows for example to have a detailed description of how 'lmcn' obtained a certain probability.
- modify
- Modify some property of the LM. In finite state based LM's derived from context free grammars, this method can be used to activate or deactivate rules.
On top of the methods provided by the LM gateway, the LM itself provides methods for:
-
Reading and writing the LM.
-
Reading external formats and converting them to one of the formats used in SPRAAK.
-
Opening and closing the evaluation gateway.
-
Freeing the LM.
Whereas the acoustic models have 'train' methods, LM's typically lack this functionality. Building LM's usually involves either manual work (e.g. context free grammars) or the collection of statistics concerning word usage patterns from large text corpora (e.g. N-grams). Both operations have little in common with the normal use of LM's in a speech recognition system and hence are better served using external methods, programs or packages.
Currently, the following LM's are available in the SPRAAK system:
-
A word based N-gram. The N-gram is designed to be both compact (low memory footprint) and fast. The down-side of being very efficient is a rigid data-layout. Hence, on-line adaptation of probabilities or any other property of the N-gram is not supported.
-
A finite state grammar/transducer (FSG/FST). The FSG is designed to be very generic while still being fairly compact and fast. The FSG supports on the fly composition and stacking. This allows the use of layered models. Stacking is used when the main model describes the high-level language constraints while sub-models describe low-level items (e.g. fixed form items such as numbers). Composition works the other way around: the main model describes low-level constraints (e.g. morphology) and accesses higher-level FSG's whenever an output symbol is generated (e.g. the morphology model has generated a complete word). The FSG has also provisions to behave exactly as an N-gram (correct fallback) and thus can replace the N-gram in situations where on-line changes to the LM are needed.
-
A probabilistic left corner grammar.
-
A direct link to the SRI LM toolkit.
-
An extension layer on top of these LM's that allow for various extensions:
-
making class based LM's
-
adding new words that behave similarly to existing words
-
allowing multiple sentences to be uttered in one go
-
adding filler words
-
adding sub-models, e.g. a phone loop model to model the out-of-vocabulary words
A last point of interest for what concerns the language model is the handling of sentence starts and sentence ends. SPRAAK allows the LM to indicate that a special sentence start symbol (usually <s>) must be pushed at the start of each new sentence. Sentence ends are treated similarly: when desired by the LM, a sentence end symbol (usually </s>) will be pushed automatically on sentence end conditions. Using special symbols to start and end sentences instead of special start and stop states in the LM (a techniques typically used in FST's) proved to be more flexible overall and has better support when using non FST-based language models.
The pronunciation network
The pronunciation network is a (possibly cyclic) finite state transducer (FST) that goes from HMM states (input symbols of the FST) to some higher level (the output symbols of the FST). Typically, the pronunciation network encodes the lexical constraints, i.e. the pronunciation of words combined with some assimilation rules, and the acoustic model constraints (context dependent phones). It is possible to encode the constraints imposed by an FST-based LM in the pronunciation network as well. For example when training the acoustic models, the sentence being spoken (a linear sequence of words) is directly encoded in the pronunciation network, eliminating the need for a language model component. Typically, the output symbols are words. Having phones as output symbols is possible and results in a phone recognizer.
Figure 1 gives an example of a pronunciation network using right context dependent phones and no assimilation rules. The final pronunciation network used by the decoder will also incorporate the tied-state information coming from the acoustic model. In order to not obscure the figure, this information was left out in the example.
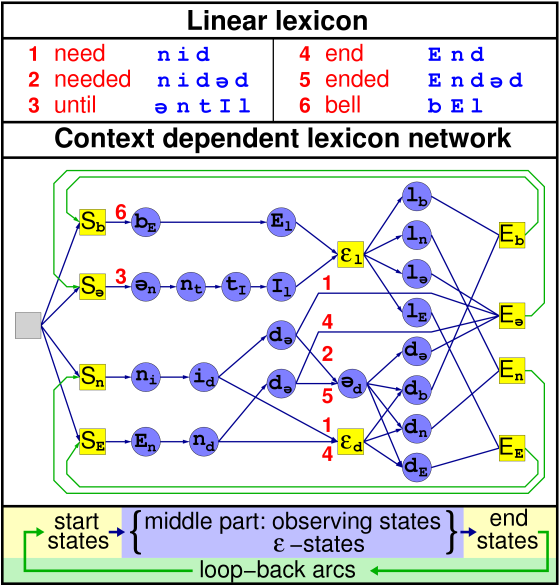
Figure 2
The pronunciation network deviates from normal FST's in several ways:
-
The input symbols are attached to the states, not the arcs. This behaviour corresponds optimally to the view SPRAAK has on the acoustic model which states that observation density functions are attached to the (hidden Markov) states. In this case, attaching the input symbols to the states in the pronunciation network eliminates the need to explicitly encode the self-loops.
-
Next to the normal observing states (the HMM states), the pronunciation network also contains some non-observing states, the most important ones being end-states. End-states indicate the end of a word and help in obtaining a fast decoder and in constructing word or phone graphs. Other non-observing states are start-states and eps-states. Eps-states serve the same purpose as eps-arcs in normal FST's. Start-states help in optimizing the pronunciation network when making a continuous loop of words (the typical configuration for large vocabulary continuous speech recognition). They also help in optimizing the word lattice.
-
The pronunciation network contains two levels of output symbols: the phone identities and the items known by the language model. Having the phone identities allows efficient back-tracking on the phone level, which in turn allows the SPRAAK decoder to store the best scoring phone transcription in its final output or in the word lattices.
The SPRAAK decoder allows loops inside the pronunciation network. However, software to optimize FST's that contain arbitrary loops is very complex and warrant toolkits to do just that [references]. All routines to optimize the pronunciation network in SPRAAK assume the straightforward configuration of the pronunciation network depicted at the bottom of figure 2. This limitation allows for far more efficient and simpler code for the construction of the pronunciation network, while in practice almost any setup can still be built. In conclusion: it is possible to build a decoder that has loops in the middle part of the above figure, however the construction of such networks will require tools from outside SPRAAK.
SPRAAK uses the following conventions for lexical transcriptions and assimilation rules:
-
The individual phones in a phonetic transcription are concatenated, i.e. they are not separated by a delimiter.
-
Phones may be represented by single and/or multiple characters, but the symbols must be chosen so that they can be parsed uniquely from left to right using a greedy algorithm, i.e. the longest phone string that matches is the correct one. Examples:
-
the set
[a/ab] is valid
-
the set
[a/ab/b] is invalid since there is no way to distinguish [ a b ] from [ ab ]
-
The following symbols are reserved:
-
the forward slash '/'
-
the square brackets '[' and ']'
-
the round braces '(' and ')'
-
the equal sign '='
-
A sequence of phones (A followed by B followed by C) is written as follows:
ABC
-
The forward slash is used to form options (A or B or nothing):
A/B/
-
Square brackets are used to group items:
A[B/CD/]E Note: [] has precedence over /
-
Nesting is allowed:
A[B/[C/D]]E
-
Probabilities can be added before any phone or before the empty set [] using a floating point value between round braces:
A[(.5)B/(.8)C(.5)D/(.1)[]]E
-
When writing assimilation rules, a single phone or the empty set [] can be replaced by another phone, by the empty set or by a complex construction:
[A/E]B=CD=[]
[A/E][]=CD=E
[A/E]B=[X/Y/[]]D=E/F
Note: square brackets can be used to make the rules more readable: [A/E][B=C]D
[A/E][[]=C]D
[A/E][B=[]]D
[A/E][B=[B/C/[]]][D=E/F]
-
When writing assimilation rules, probabilities can only be added at the right hand side of the '=' sign:
[A/E][B=[(.1)B/(.7)C/(.2)[]]]D
This 'flat' notation strikes a good balance between readability and expressiveness. In the few cases very complex descriptions are needed, the following formats can be used:
=<nr_of_nodes>[<from_node>/<to_node>/(<prob>)<phone>]...
=<nr_of_nodes>[<from_node>/<to_node>/<phone>=(<prob>)<phone>]...
The (<prob>) fields are optional. For example, the assimilation rule
[A/E][B=[(.1)B/(.7)C/(.2)[]]]D
can also be written as:
=4[0/1/A][0/1/E][1/2/B=(.1)B][1/2/B=(.7)C][1/2/B=(.2)[]][2/3/D]
SPRAAK contains several tools to help in constructing the pronunciation network:
-
Lexica can be read and converted to FST's.
-
Assimilation rules can be read and converted to FST's.
-
The description of the tied-state context-dependent phones can be read and converted to a FST.
-
Orthographic transcriptions can be read and converted to a FST. These orthographic transcriptions may even contain altervatives:
... apple computer [ inc. / incorporated ] ...
-
All resources can be combined using FST composition.
-
Using off-line tools, most language models can be converted to FST's, allowing the integration of the LM constraint into the pronunciation network.
The search engine (decoder)
The search engine finds the best path through the search space defined by the acoustic model, the language model and the pronunciation network given the acoustic data coming from the preprocessing block.
The search engine is a breath-first frame synchronous decoder which is designed to:
-
Impose as few constraints on the resources as possible. The SPRAAK decoder allows cross-word context-dependent tied-state phones, multiple pronunciations per word, assimilation rules, and any language model that can be written in a left-to-right conditional form.
-
Be exact. No approximations whatsoever are used during the decoding. All resources are combined exactly as the theoretic framework postulates. The only obstacle that prevents the decoder from finding the exact solution all of the times is the pruning.
-
Provide rich output. The decoder can output the single best output as well as (word) lattices. Both output can be generated on-the-fly and with low latency. The back-tracking can be instructed to keep track of the underlying phone or state sequences and to add them recognized word string and/or store them alongside the (word) lattice.
-
Be efficient. Using a clever design, all of the above can be (and is) achieved in a decoder capable of real-time decoding even for the demanding task such a large vocabulary speech recognition.
Other important properties of the decoder are:
-
The decoder adapts itself to the resources it must combined. Based on the required interaction between the components, the most efficient implementation is chosen automatically. The different decoders are derived from the same source code using the 'template; technique (see Templates and optimal task-specific implementations).
-
Observer objects (see Observers) allow for advanced interaction schemes such as feedback-loops (e.g. unsupervised adaptation of acoustic or language models, or even the preprocessing).
-
The search can be paused or stopped based on external events. When paused, a result can be obtained as if there was a sentence end at this point. This allows interactive systems to test different possible end-points.
-
The search can be instructed to allow restarting the search at a certain point in time. This allows for unsupervised adaptation schemes that sense that their estimate is either that much improved or completely off that is would be better to reprocess the old data.
-
Since the pronunciation network marks word endings, the start of a new word can be easily detected and extra external inputs (e.g. prosodic information) can be used to control or guide this process.
(Word) lattice (post)-processing
The (word) lattice (post)-processing consists, similar to the preprocessing, of a fully configurable processing flow-chart and a large set of processing blocks. The lattice processing can be fed either from stored lattices or can be coupled directly to decoder using the built-in lattice generator.
The most important properties of lattice processing component are:
-
A low-latency data driven design. All events (arcs and nodes) are sent to through the lattice processing system as soon as they are generated. All blocks are designed to cope with a continuous flow of events and where possible, are designed to be low-latency. This allows the use of the lattice post-processing system even in interactive systems.
-
Lattices in SPRAAK are built based on the pronunciation information only. All information that comes from a separate language model component is not included in the lattices. Having only acoustic information in the lattice results in more compact and at the same time more generalizing lattices. There is a module to introduce language model constraints (and scores) in the lattice if this is needed.
-
The lattice system allows for extra information to be passed along on both the arcs and the nodes. This allows for example to attach phonetic transcriptions to the word arcs.
-
In order to avoid cumbersome checking of these properties in each module, SPRAAK allows the modules to assume that the properties are met (resulting in crashes if this is not the case). A generic check module can be inserted before other modules to assure that either everything works as advertised or that a well formatted error message is given and the processing is stopped properly (no program crash).
-
SPRAAK uses its own lattice format. None of the existing formats supported all of the features listed above (continuous processing, low-latency, extra events, ...). There is support for common other lattice formats (reading and writing), but functionality will be limited due to the inherent limitations of these other formats.
-
As is the case with
Among the available processing modules are:
Other objects
Todo


 1.8.6
1.8.6