Overview
Figure 1 shows the main components of the SPRAAK recognizer in a typical configuration and with the default interaction between these components. "SPRAAK Architecture and Components"
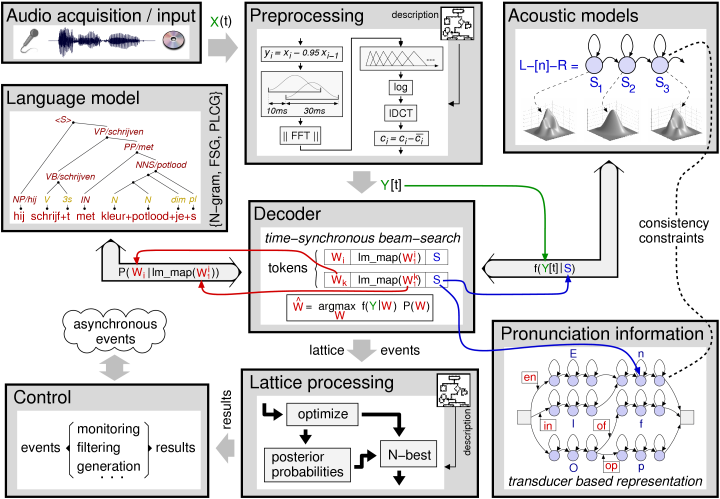
Figure 1
In a large vocabulary speech recognition application typically all components will be activated. When using the SPRAAK engine for other tasks (e.g. preprocessing, alignment, training of acoustic models, ... ), only a subset of the same main components may be used. For highly experimental setups more complex configurations and interactions are possible.
The components shown in figure 1 are:
-
the preprocessing
-
the acoustic model (AM)
-
the lexicon containing pronunciation information, organized as a network / finite state transducer
-
the language model (LM)
-
the decoder which connects all major components together
-
a lattice generation and processing block
A detailed description of the underlying software implementation may be found in the developer's manual. Here we give a brief functional description of each of these modules.
The preprocessing
The preprocessing converts audio data (or half preprocessed features) to a (new) feature stream. The preprocessing is described in a dedicated preproc-file as a fully configurable processing flow-chart.
Available processing modules include:
-
spectral analysis
-
cepstral analysis
-
LPC, PLP analysis
-
mean(+variance) normalization and histogram normalization
-
vocal tract length normalization
-
noise tracking and noise normalization
-
silence speech detection
-
pitch tracking
-
speech synthesis
-
basic mathematical operations, including matrix multiplies, time derivatives, ... which allows to implement feature based speaker adaptation, LDA transforms, extended features sets, ..
-
VQ, GMMs, (D)NNs, HMMs and other probabilistic classifiers
-
data IO, i.e. reading preprocessed data generated with other programs or dumping intermediate results for debugging
Important properties and constraints of the preprocessing module are:
-
Non-causal behaviour is supported by allowing the process routine to withhold data whenever deemed necessary
-
All preprocessing can be done both on-line and off-line
-
The fact that everything is available on-line is very handy, but requires some programming effort when writing new modules since everything has to be written to work on streaming data.
-
Currently, only a single frame clock is supported. Changing the frame-rate (dynamically or statically) is not supported.
-
Frames must be processed in order and are returned in order.
See Also: Feature Extraction
The acoustic model
The acoustic model calculates observation likelihoods for the Hidden Markov States (HMM) states.
Features are:
- DNNs
-
fast CPU-based (no GPU required) DNNs (evaluation only, training will require a GPU but is not yet implemented)
-
also legacy MLP implementation with, amongst others, a novel fast hierarchical (and hence deep) structure (CPU-based; also with Viterbi-based training)
- GMMs
-
mixture gaussian densities with full sharing
-
fast evaluation for tied Gaussians by data-driven pruning based on 'Fast Removal of Gaussians' (FRoG)
-
model topoplogy is decoupled from observation likelihoods, allowing for any number of states in any phone sized unit
-
dedicated modules for initializing and updating the acoustic models (training and/or speaker adaptation)
-
access to all components of the acoustic model (the Gaussian set, FRoG, ...)
- Other
-
legacy implementations for discrete density models
Lexicon and Pronunciation Network
The lexicon is stored as pronunciation network in a (possibly cyclic) finite state transducer (FST) that goes from HMM states (input symbols of the FST) to some higher level (the output symbols of the FST). Typically, the output symbols are words. Having phones as output symbols is possible and results in a phone recognizer.
Apart from (word) pronunciations as such, this network can also encode assimilation rules and may use context dependent phones as learned by the acoustic model.
The same network may also be used to the constraints imposed by an FST-based LM. For example when training the acoustic models, the sentence being spoken (a linear sequence of words) is directly encoded in the pronunciation network, eliminating the need for a language model component.
Figure 2 gives an example of a pronunciation network using right context dependent phones and no assimilation rules. The final pronunciation network used by the decoder will also incorporate the tied-state information coming from the acoustic model. In order to not obscure the figure, this information was left out in the example.
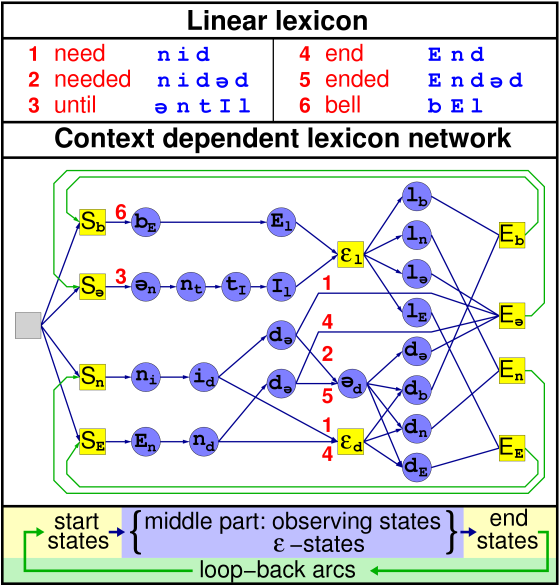
Figure 2: Lexical Network
The pronunciation network deviates from normal FST's in several ways:
-
The input symbols are attached to the states, not the arcs.
-
The network also contains some non-observing states: end-states, start-states and eps-states
-
The network contains two levels of output symbols: the phone identities and the items known by the language model.
-
loops are allowed inside the pronunciation network
See Also: Acoustic Model
The language model
The language model (LM) calculates conditional word probabilities, i.e. the probability of a new word given its predecessor words. For efficiency reasons the LM condenses all relevant information concerning the word predecessors in its own state variable(s).
Supported LM's and interfaces are:
-
A word based N-gram which has a low memory footprint and is fast.
-
A finite state grammar/transducer (FSG/FST). The FSG supports on the fly composition and stacking. The FSG has also provisions to behave exactly as an N-gram (correct fallback) and thus can replace the N-gram in situations where on-line changes to the LM are needed.
-
An LM combiner, e.g. combine (partial) TV-scripts in FSG format with a large N-gram background model to sub-title TV broadcast shows.
-
A probabilistic left corner grammar.
-
A direct link to the SRI LM toolkit.
Furthermore an extension layer on top of these LM's allows for various extensions:
-
making class based LM's
-
adding new words that behave similarly to existing words
-
allowing multiple sentences to be uttered in one go
-
adding filler words
-
adding sub-models, e.g. a phone loop model to model the out-of-vocabulary words
See Also: Language Model
The decoder
The decoder (search engine) finds the best path through the search space defined by the acoustic model, the language model and the pronunciation network given the acoustic data coming from the preprocessing block.
SPRAAK implements an efficient all-in-one decoder with as main features:
-
Breath-first frame synchronous.
-
Allows cross-word context-dependent tied-state phones, multiple pronunciations per word, assimilation rules, and any language model that can be written in a left-to-right conditional form.
-
Exact, i.e. no approximations whatsoever are used during the decoding, except for the applied pruning.
-
Low-overhead "histogram" pruning implemented via an adaptive threshold (feedback control loop).
-
Provides both the single best output and word lattices. All outputs can be generated on-the-fly and with low latency.
-
compact word lattices: since the LM is factored out, the lattices are moderate in size.
-
The back-tracking can be instructed to keep track of the underlying phone or state sequences and to add them recognized word string and/or store them alongside the (word) lattice.
(Word) lattice (post)-processing
The (word) lattice (post)-processing consists, similar to the preprocessing, of a fully configurable processing flow-chart and a large set of processing blocks. The lattice processing can be fed either with stored lattices or can be coupled directly to the decoder using the built-in lattice generator.
The most important properties of lattice processing component are:
-
A low-latency data driven design suitable for use in real-time applications
-
Lattices contain only acoustic model scores
-
Weak consistency checks when rescoring for speed reasons (but may result in crashes if inconsistent knowledge sources are applied)
Among the available processing modules are:
See Also


 1.8.6
1.8.6